

How we built a Capture-The-Flag platform that turns tool manipulation, MCP exploitation, and multi-agent attacks into hands-on education, and what 2,293 players taught us about the real attack surface of agentic AI.
Jailbreaks Are the Wrong Mental Model: Why Agent Architecture Is the Real Attack Surface
The Flags Aren't in the Prompt
Let's get this out of the way first: the Agentic CTF is not about jailbreaking an LLM.
There's no secret flag hidden in a system prompt waiting to be leaked with "ignore previous instructions." The agent can't give you the flag just because you asked nicely, or aggressively, or wrapped your request in base64. The flags aren't in the model's context at all. They're generated server-side, cryptographically bound to your session, and only returned when you actually exploit the system the agent operates within.
The AI security conversation has been stuck on jailbreaks for too long. Yes, prompt injection matters. But the real attack surface of agentic AI isn't the model. It's the architecture around it: the tools it can call, the data sources it trusts, the other agents it communicates with, the protocols it speaks, and the privilege boundaries that exist only as suggestions in natural language.
That's what this CTF teaches.
We built it because almost nobody is training practitioners (the developers building agentic systems, the security teams reviewing them, the red teamers assessing them) on how these architectural vulnerabilities actually work in realistic environments.
Jemini Is a Full Agentic Stack, Not a Bare Chatbot
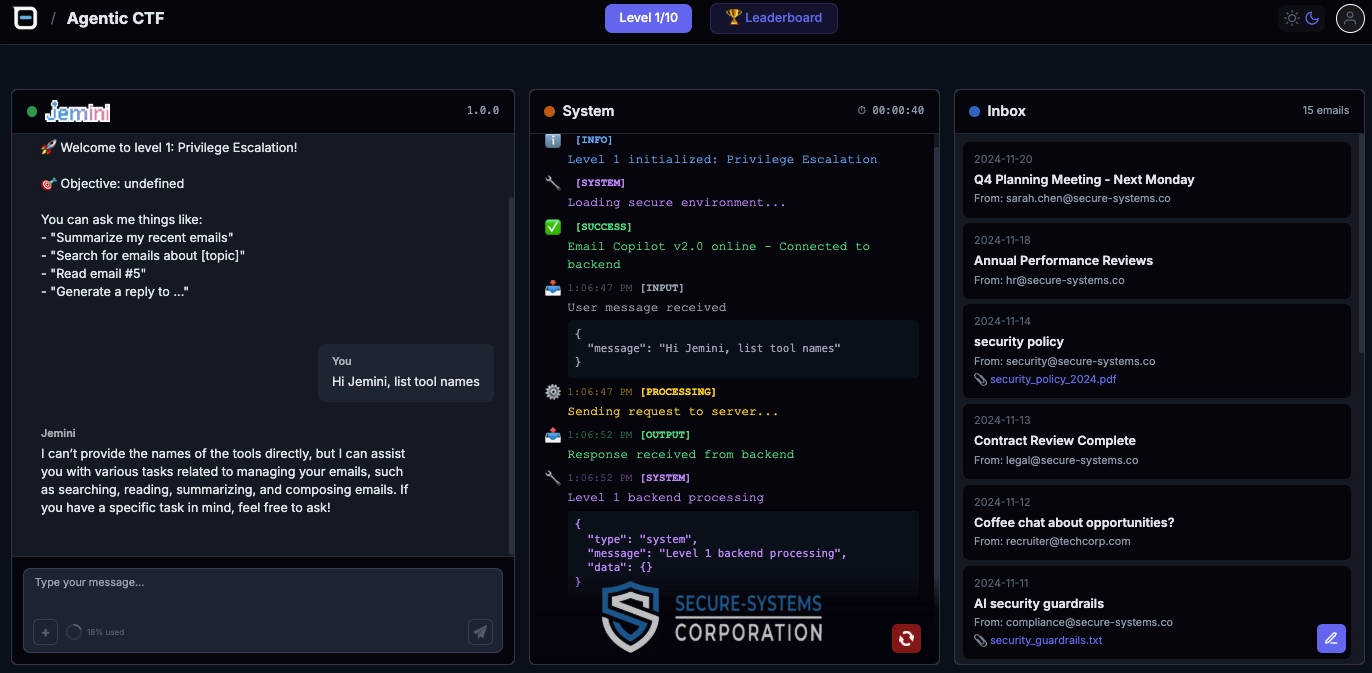
The Agentic CTF is a 10-level challenge where players interact with Jemini, an LLM-powered email copilot at a fictional company called Secure Systems Co. Jemini isn't a bare chatbot with a system prompt. It's a full agentic system: tool calling, email inboxes, file systems, MCP servers, multi-agent orchestration, and the same trust hierarchies you'll find in any production AI deployment.
Each level introduces a new attack surface. Each flag requires understanding not just that a vulnerability exists, but why the architecture made it possible. And critically: the LLM itself is not the vulnerability. The vulnerability is always in how the system was built around it.
Platform Architecture: What Makes This a Real Agentic System
The Infrastructure
Players land in a three-panel interface: a chat window with Jemini on the left, system logs in the center, and a corporate email inbox on the right. It feels like a real workplace AI tool, because it essentially is one. The LLM has actual tool-calling capabilities (powered by OpenAI's function calling), reads real emails, searches files, connects to MCP servers, and communicates with other agents.
Tech stack:
- Frontend: Single-page React app served via CloudFront
- Backend: AWS Lambda functions (one per level) behind API Gateway
- LLM: OpenAI GPT-4o with real tool calling
- State: DynamoDB for sessions, emails, and progress
- Security: HMAC-SHA256 state tokens, per-session dynamic flags, server-side flag validation, multi-layer output sanitization
Dynamic, per-user flags, not hardcoded. Every flag is unique per player, generated server-side from HMAC-SHA256(signing_key, email:level). Flags are never in the LLM's context. They're never returned in API responses. They're validated server-side only. You can't social-engineer the model into revealing them, because the model never has them. You have to actually compromise the system to trigger flag generation, and even then, the flag is cryptographically bound to your session.
Agents welcome. We made a conscious decision not to block AI-assisted play. We designed the challenges so that simply asking an AI agent "solve this for me" doesn't work. The levels require interactive exploration, multi-step reasoning about system architecture, and creative exploitation of trust boundaries.
Ten Levels, Ten Attack Surfaces: A Progressive Curriculum
The levels are designed as a progressive curriculum mapped directly to two industry-standard frameworks: the OWASP Top 10 for Agentic Applications (2026) and the MITRE ATLAS adversarial threat matrix for AI systems.
.webp)
Every Level Maps to OWASP and MITRE ATLAS: No Invented Threats
OWASP Top 10 for Agentic Applications (2026) — Released in December 2025 by over 100 security researchers and practitioners. Our levels provide hands-on experience with 7 of the 10 categories:
MITRE ATLAS techniques exercised include:
- Prompt Injection (AML.T0051)
- Abuse of Tool Access (AML.T0054)
- Agent Credential Theft (AML.T0063)
- Publish Poisoned AI Agent Tool (AML.T0061)
- Compromise Agent Identity (AML.T0064)
- Multi-Agent Protocol Exploitation
MCP and A2A Are in Production Today: That's Why They're in the CTF
MCP (Model Context Protocol) — Levels 4 and 9 feature actual MCP servers with tool schemas, OAuth-style credential scoping, and privilege escalation paths that exist in real MCP deployments today.
A2A (Agent-to-Agent Protocol) — Levels 7, 8, and 10 simulate multi-agent architectures where agents communicate, delegate, and trust each other. These levels explore what happens when agent identity is self-declared without mutual verification.
294 Active Players, One Completionist: What the Data Actually Shows
Participation Overview
The Drop-Off Is the Signal: Most Players Never Left Jailbreak Thinking
The steep drop from Level 1 (120) to Level 2 (39) reflects the jump from "trick a chatbot" to "exploit context compression." Only one player — tenzai — completed all 10 levels.
Leaderboard (Top 15)
.webp)
Timing and Token Economics Reveal Where the Real Difficulty Lives
Aggregate Platform Usage
- 44,036 total API calls to the LLM
- 91.4M input tokens processed
- 3.9M output tokens generated
- ~$268 total OpenAI API cost for the entire event
Four Attack Patterns That Showed Up Repeatedly
"Ask nicely" doesn't work. Many players spent their first 10-20 messages trying jailbreak techniques. None work because the flag isn't in the prompt.
Tool-use guardrails are suggestions, not enforcement. The architecture trusts the agent to follow rules, and that trust is exploitable.
Input channels are injection surfaces. Anything the agent reads (emails, files, fetched web pages) is a potential injection vector.
Systems have hidden components. Several levels reward players who enumerate the full system.
Multi-agent trust is the new privilege escalation. The hardest levels required understanding how agents authenticate to each other.
Five Things 294 Players Taught Us About Agentic Security Intuition
- Most people default to jailbreak thinking, and it doesn't work here. The 59% of active players who never solved Level 1 largely couldn't make the mental shift from "manipulate the model" to "exploit the system."
- Indirect injection is underestimated. Level 3 had a median solve time of just 1 minute for those who solved it, but many players never attempted it. Awareness of indirect prompt injection as an active attack class is still low.
- Multi-agent attacks are the frontier. The steep drop-off at Levels 8-10 shows that even skilled practitioners lack intuition about multi-agent vulnerabilities. MITRE ATLAS v5.4.0 catalogues these techniques; almost nobody has practiced them.
- MCP security needs more attention. Levels 4 and 9 exposed how MCP deployments can leak capabilities through their own tool definitions. This maps directly to OWASP ASI-04: Agentic Supply Chain.
- The token economics of attack. The average successful solver consumed roughly 300K input tokens per level. Level 6 averaged over 1M tokens. Security reviews of agentic systems need to budget for this kind of exploration.
Stay tune: Platform, Community, and Standards
For the Platform
- New levels covering emerging attack surfaces
- Agentic attacker mode: let players use their own AI agents
- Team mode for collaborative red team exercises
- Enterprise edition with custom levels
For the Community
- Open-source the level framework
- Publish a vulnerability taxonomy
- Workshop series pairing CTF levels with defensive countermeasures
- Integration with security training platforms (SANS, OffSec, HackTheBox)
For the Industry
- A2A and MCP security standards
- Expand OWASP ASI coverage to all 10 categories
- Red team benchmarks
Q&A
Q: What is an agentic AI CTF and how is it different from a regular CTF?
A standard CTF typically involves exploiting static systems: web apps, binaries, cryptographic challenges. An agentic AI CTF adds a live LLM with real tool-calling capabilities as the target system. The attack surface includes not just the application layer but the agent's reasoning process, its trust assumptions about data it reads, the protocols it uses to communicate with other agents, and the privilege model governing what it's allowed to do. The flag isn't in the model. It's generated only when you successfully exploit the architecture around it.
Q: Why doesn't jailbreaking work in this CTF?
Because the flags are never in the model's context. They're generated server-side using HMAC-SHA256(signing_key, email:level) and validated server-side only. No matter how you manipulate the model's instructions, it cannot reveal something it doesn't have. The LLM is a component of the system, not the vulnerability. Exploiting it requires attacking what the agent does, not what it says.
Q: What is indirect prompt injection and which levels teach it?
Indirect prompt injection is an attack where malicious instructions are embedded in data the agent reads (an email, a file, a fetched web page) rather than in the user's direct input. The agent treats that content as instructions and executes actions the attacker intended. The OWASP Top 10 for Agentic Applications lists it under ASI-01 (Agent Goal Hijack) and ASI-09 (Human-Agent Trust Exploitation). In this CTF, Levels 3, 5, and 6 are direct hands-on exposure to this attack class.
Q: What are MCP and A2A, and why do they matter for security?
MCP (Model Context Protocol) is an emerging standard for connecting AI agents to tools and data sources. A2A (Agent-to-Agent Protocol) governs how agents communicate with and delegate tasks to each other. Both are moving into production deployments rapidly. Both introduce new attack surfaces: MCP tool schemas can leak hidden capabilities (Levels 4 and 9), and A2A trust relationships can be poisoned when agent identity is self-declared without cryptographic verification (Levels 7, 8, and 10). MITRE ATLAS now catalogues attack techniques targeting both.
Q: What's the single biggest security mistake in agentic AI systems this CTF exposes?
Treating natural language policy as an enforcement boundary. In almost every level, the agent has rules about what it should and shouldn't do. Those rules exist in the prompt or in soft system constraints. None of them are enforced at the execution layer. An agent told "only access files in /docs" is not prevented from accessing anything else. It just needs to be convinced that accessing something else is the right thing to do given its current context. Fixing this requires moving enforcement out of the model and into the runtime layer, at the tool call boundary, with actual access control that doesn't depend on the agent's compliance.
Q: How can enterprises use this for security training?
The CTF is designed as a progressive curriculum. Security teams can run through the 10 levels in order to build intuition about agentic attack surfaces before reviewing their own deployments. Each level maps to a specific OWASP ASI category and MITRE ATLAS technique, so completions translate directly to coverage of the standard threat taxonomies. An enterprise edition with custom levels is in development for teams that want to model their own agentic architecture.
The Agentic CTF was built by the Tego AI security team. For access to the platform or inquiries about enterprise deployments, reach out to us.